diff --git a/docs/figures/bias_hist.png b/docs/figures/bias_hist.png
new file mode 100644
index 0000000..056d985
Binary files /dev/null and b/docs/figures/bias_hist.png differ
diff --git a/docs/figures/bias_publisher_hist.png b/docs/figures/bias_publisher_hist.png
new file mode 100644
index 0000000..b0dae0a
Binary files /dev/null and b/docs/figures/bias_publisher_hist.png differ
diff --git a/docs/figures/bias_vs_recent_winner.png b/docs/figures/bias_vs_recent_winner.png
new file mode 100644
index 0000000..7da9404
Binary files /dev/null and b/docs/figures/bias_vs_recent_winner.png differ
diff --git a/docs/figures/bias_vs_sentiment_over_time.png b/docs/figures/bias_vs_sentiment_over_time.png
new file mode 100644
index 0000000..18d0b00
Binary files /dev/null and b/docs/figures/bias_vs_sentiment_over_time.png differ
diff --git a/docs/figures/link_confusion.png b/docs/figures/link_confusion.png
new file mode 100644
index 0000000..d6b2a74
Binary files /dev/null and b/docs/figures/link_confusion.png differ
diff --git a/docs/figures/raw_bias_table.png b/docs/figures/raw_bias_table.png
new file mode 100644
index 0000000..8823d88
Binary files /dev/null and b/docs/figures/raw_bias_table.png differ
diff --git a/docs/figures/raw_emotion_table.png b/docs/figures/raw_emotion_table.png
new file mode 100644
index 0000000..85a06f9
Binary files /dev/null and b/docs/figures/raw_emotion_table.png differ
diff --git a/docs/figures/raw_related_table.png b/docs/figures/raw_related_table.png
new file mode 100644
index 0000000..b9e08cc
Binary files /dev/null and b/docs/figures/raw_related_table.png differ
diff --git a/docs/figures/raw_sentiment_table.png b/docs/figures/raw_sentiment_table.png
new file mode 100644
index 0000000..8790d5d
Binary files /dev/null and b/docs/figures/raw_sentiment_table.png differ
diff --git a/docs/figures/raw_stories_table.png b/docs/figures/raw_stories_table.png
new file mode 100644
index 0000000..7f53533
Binary files /dev/null and b/docs/figures/raw_stories_table.png differ
diff --git a/docs/figures/selected_bias_table.png b/docs/figures/selected_bias_table.png
new file mode 100644
index 0000000..f63adc8
Binary files /dev/null and b/docs/figures/selected_bias_table.png differ
diff --git a/docs/presentation.md b/docs/presentation.md
index 26e2538..e781ad7 100644
--- a/docs/presentation.md
+++ b/docs/presentation.md
@@ -6,35 +6,71 @@ title: CSCI 577 - Data Mining
---
body:
+
+
+
# Political Polarization
-Matt Jensen
+## CSCI 577
+
+**Matt Jensen**
+
+*May 18, 2023*
+
+==
+
+# Outline
+
+- Hypothesis
+- Sources
+- Data Workup
+- Experiments
+- Remaining Work
+- Questions
===
+
+
+# Hypothesis
+
+==
+
# Hypothesis
Political polarization is rising, and news articles are a proxy measure.
==
-# Is this reasonable?
+# Why might we expect this?
+
+Mostly anecdotal experience.
-==
+
+ Evidence is mixed in the literature
+ 1,2,3.
+
-# Why is polarization rising?
-
-Not my job, but there's research[ref](#references) to support it
+Our goal is whether, not why.
+Note:
+> Proliferation of media choices lowered the share of less interested, less partisan
+> voters and thereby made elections more partisan. But evidence for a causal
+> link between more partisan messages and changing attitudes or behaviors is
+> mixed at best. Measurement problems hold back research on partisan selec-
+> tive exposure and its consequences. Ideologically one-sided news exposure
+> may be largely confined to a small, but highly involved and influential, seg-
+> ment of the population. There is no firm evidence that partisan media are
+> making ordinary Americans more partisan.
==
# Sub-hypothesis
-- The polarization increases near elections.
- The polarization is not evenly distributed across publishers.
- The polarization is not evenly distributed across political specturm.
+- The polarization increases near elections.
==
@@ -44,28 +80,48 @@ Not my job, but there's research[ref](#references) to support it
- 'Mainstream' media uses more neutral titles.
- Highly polarized publications don't last as long.
+Note:
+
+- Publication longivity is not covered currently.
+- Mainstream media dominates the dataset.
+
===
-# Data Source(s)
+
-memeorandum.com
+# Data Sources
-allsides.com
+==
-huggingface.com
+# Data Sources
+
+- Memeorandum: **stories**
+- AllSides: **bias**
+- HuggingFace: **sentiment**
+- ChatGPT: **election dates**
Note:
+
Let's get a handle on the shape of the data.
-The sources, size, and features of the data.
+- sources
+- size
+- features
+
===
-
+
-===
+# Memeorandum
-# memeorandum.com
+==
+
+
+
+==
+
+# Memeorandum
- News aggregation site.
- Was really famous before Google News.
@@ -73,109 +129,92 @@ The sources, size, and features of the data.
==
-# Why Memeorandum?
+# Memeorandum
-- Behavioral: I only read titles sometimes. (doom scrolling).
-- Behavioral: It's my source of news (with sister site TechMeme.com).
-- Convenient: most publishers block bots.
-- Convenient: dead simple html to parse.
-- Archival: all headlines from 2006 forward.
-- Archival: automated, not editorialized.
+- I still use it.
+- I like to read titles.
+- Publishers block bots.
+- Simple html to parse.
+- Headlines from 2006 forward.
+- Automated, not editorialized.
+
+Note:
+
+- It limits doom scrolling.
===
-
+
-===
+# AllSides
-# AllSides.com
+==
-- Rates news publications as left, center or right.
+
+
+==
+
+# AllSides
+
+- Rates publications as left, center or right.
- Ratings combine:
- blind bias surveys.
- editorial reviews.
- third party research.
- community voting.
-- Originally scraped website, but direct access eventually.
+Note:
+Originally scraped website, but direct access eventually.
==
-# Why AllSides?
+# AllSides
-- Behavioral: One of the first google results on bias apis.
-- Convenient: Ordinal ratings [-2: very left, 2: very right].
-- Convenient: Easy format.
-- Archival: Covers 1400 publishers.
+- One of the only bias apis.
+- Ordinal ratings [-2: very left, 2: very right].
+- Covers 1400 publishers + some blog and authors.
+- Easy format and semi-complete data.
===
-
+
-===
+# HuggingFace
-# HuggingFace.com
+==
-- Deep Learning library.
+
+
+==
+
+# HuggingFace
+
+- Deep learning library.
- Lots of pretrained models.
- Easy, off the shelf word/sentence embeddings and text classification models.
==
-# Why HuggingFace?
+# HuggingFace
-- Behavioral: Language Models are HOT right now.
-- Behavioral: The dataset needed more features.
-- Convenient: Literally 5 lines of python.
-- Convenient: Testing different model performance was easy.
-- Archival: Lots of pretrained classification tasks.
+- Language models are **HOT**.
+- Literally 5 lines of python.
+- The dataset needed more features.
+- Testing different model performance was easy.
+- Lots of pretrained classification tasks.
===
-# Data Structures
+
+
+# Data Collection
+
+==
+
+# Data Collection
+
## Stories
-- Top level stories.
- - title.
- - publisher.
- - author.
-- Related discussion.
- - publisher.
- - uses 'parent' story as a source.
-- Stream of stories (changes constantly).
-
-==
-
-# Data Structures
-## Bias
-
-- Per publisher.
- - name.
- - label.
- - agree/disagree vote by community.
-- Name could be semi-automatically joined to stories.
-
-==
-
-# Data Structures
-## Embeddings
-
-- Per story title.
- - sentence embedding (n, 384).
- - sentiment classification (n, 1).
- - emotional classification (n, 1).
-- ~ 1 hour of inference time to map story titles and descriptions.
-
-===
-
-# Data Collection
-
-==
-
-# Data Collection
-
-## Story Scraper (simplified)
-
```python
day = timedelta(days=1)
cur = date(2005, 10, 1)
@@ -189,11 +228,17 @@ while cur <= end:
f.write(r.text)
```
+Note:
+
+grab every page from 2005 forward.
+
+later: parse it into csv/database.
+
==
# Data Collection
-## Bias Scraper (hard)
+## Bias **hard**
```python
...
@@ -209,19 +254,30 @@ for row in rows:
...
```
+Note:
+
+grab entire index
+
+later parse it into csv/database
+
==
# Data Collection
-## Bias Scraper (easy)
+## Bias **easy**
+
+Note:
+
+json format, including authors and blogs.
+
==
# Data Collection
-## Embeddings (easy)
+## Embeddings
```python
# table = ...
@@ -235,11 +291,17 @@ for chunk in table:
...
```
+Note:
+
+for every title, tokenize then embed.
+
+hidden state is last linear layer before training tasks.
+
==
# Data Collection
-## Classification Embeddings (medium)
+## Classification Embeddings
```python
...
@@ -251,58 +313,57 @@ for i, class_id in enumerate(class_ids):
...
```
+Note:
+
+for every title, tokenize, classify.
+
+~ 1 hour
+
===
-# Data Selection
-
-==
-
-# Data Selection
+
+# Data Structures
## Stories
-- Clip the first and last full year of stories.
-- Remove duplicate stories (big stories span multiple days).
+Note:
-==
-# Data Selection
-
-## Publishers
-
-- Combine subdomains of stories.
- - blog.washingtonpost.com and washingtonpost.com are considered the same publisher.
- - This could be bad. For example: opinion.wsj.com != wsj.com.
+Great, we have the data, now what does it look like?
==
-# Data Selection
+# Data Structures
-## Links
+## Stories
-- Select only stories with publishers whose story had been a 'parent' ('original publishers').
- - Eliminates small blogs and non-original news.
-- Eliminate publishers without links to original publishers.
- - Eliminate silo'ed publications.
- - Link matrix is square and low'ish dimensional.
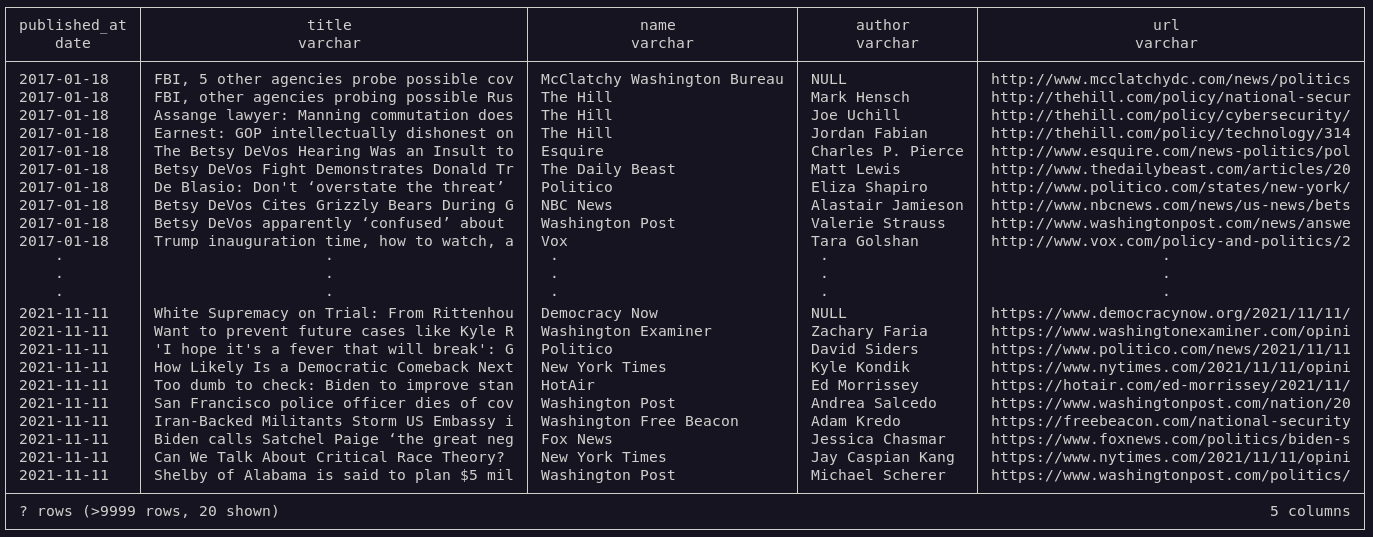
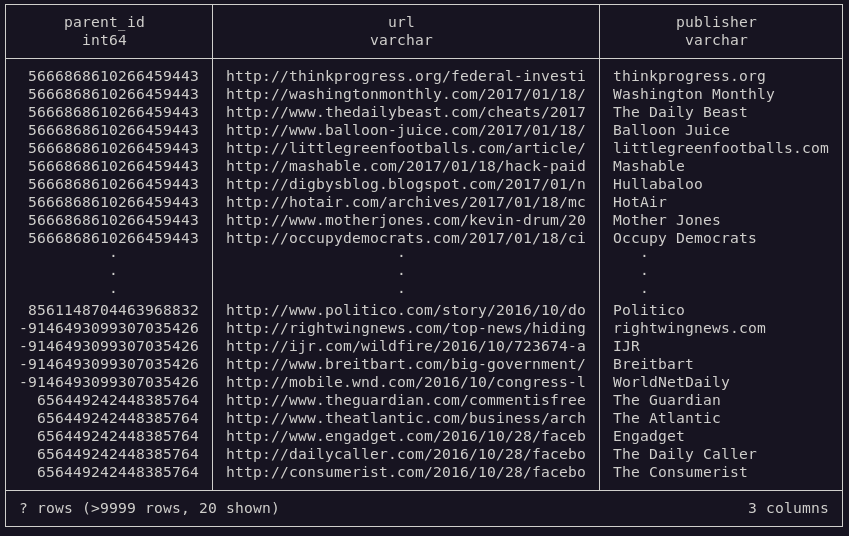
+- Top level stories.
+ - title, author, publisher, url, date.
+- Related discussion.
+ - publisher, url.
+ - uses 'parent' story as a source.
+- Story stream changes constantly (dedup. required).
==
-# Data Selection
+# Data Structures
-## Bias
+## Stories
-- Keep all ratings, even ones with low agree/disagree ratio.
-- Join datasets on publisher name.
- - Not automatic (look up Named Entity Recognition).
- - Started with 'jaro winkler similarity' then manually from there.
-- Use numeric values
- - [left: -2, left-center: -1, ...]
+
-===
+==
-# Descriptive Stats
+# Data Structures
-## Raw
+## Stories
+
+
+
+==
+
+# Data Structures
+
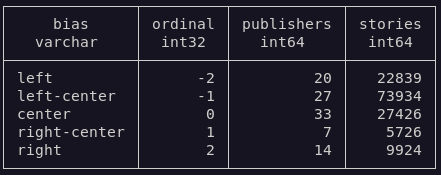
+## Stories
| metric | value |
|:------------------|--------:|
@@ -315,39 +376,53 @@ for i, class_id in enumerate(class_ids):
| top level domains | 7063 |
==
-# Descriptive Stats
-## Stories Per Publisher
+# Data Selection
-
+## Stories
+
+- Clip the first and last full year of stories.
+- Remove duplicate stories (big stories span multiple days).
+- Convert urls to tld to link to publishers.
+
+Note:
+
+tld: top level domain.
==
-# Descriptive Stats
+# Data Selection
-## Top Publishers
+## Publishers
-
+- Combine subdomains of stories.
+ - blog.washingtonpost.com and washingtonpost.com are considered the same publisher.
+ - This could be bad. For example: opinion.wsj.com != wsj.com.
+- Find common name of publisher.
+
+Note:
+
+Sometime authors are the publisher name.
==
-# Descriptive Stats
+# Data Selection
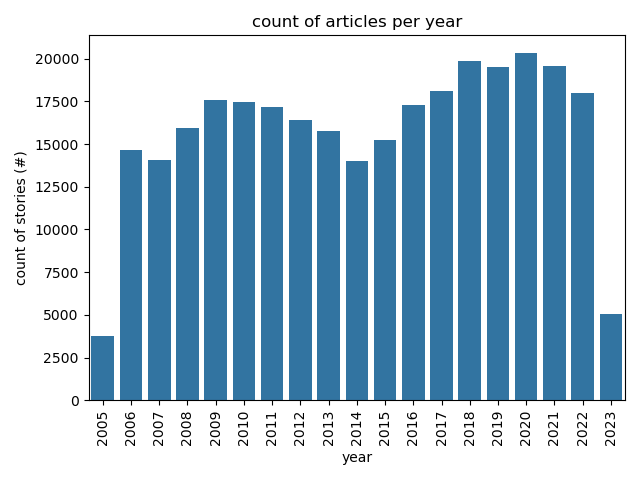
-## Articles Per Year
+## Related
-
+- Select only stories with publishers whose story had been a 'parent' ('original publishers').
+ - Eliminates small blogs and non-original news.
+- Eliminate publishers without links to original publishers.
+ - Eliminate silo'ed publications.
+ - Link matrix is square and low'ish dimensional.
+
+Note:
+
+Going to build a data structure of the related links, so I have to be judicious about which ones to include.
==
-# Descriptive Stats
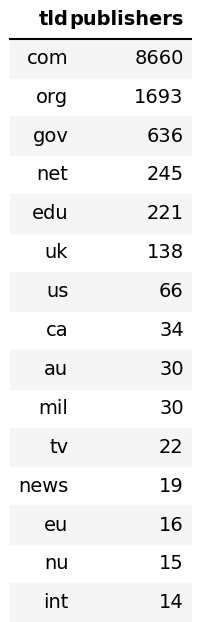
-
-## Common TLDs
-
-
-
-==
-
-# Descriptive Stats
+# Data Selection
## Post Process
@@ -361,18 +436,230 @@ for i, class_id in enumerate(class_ids):
| min year | 2006 |
| top level domains | 234 |
+Note:
+
+much less publishers, but count(stories) about the same - main stream represent.
+
+==
+
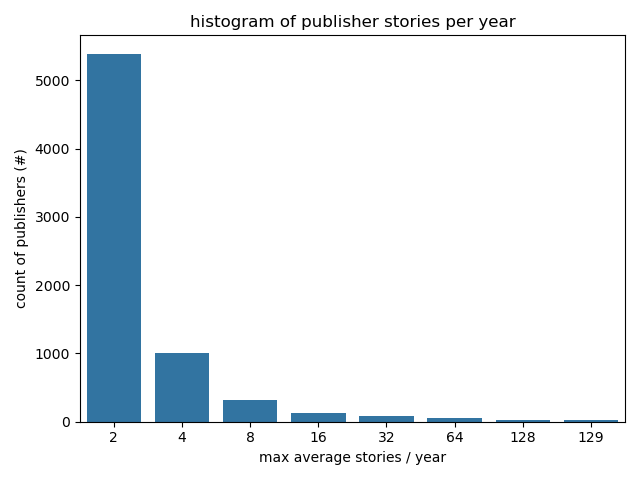
+# Descriptive Stats
+
+## Stories Per Publisher
+
+
+
+Note:
+
+Power law in effect.
+
+==
+
+# Descriptive Stats
+
+## Top Publishers
+
+
+
+Note:
+
+Some publishers come and go.
+
+Some publishers change their domains.
+
+==
+
+# Descriptive Stats
+
+## Articles Per Year
+
+
+
+Note:
+
+Shape of total articles per year dominates some of the analysis.
+
+==
+
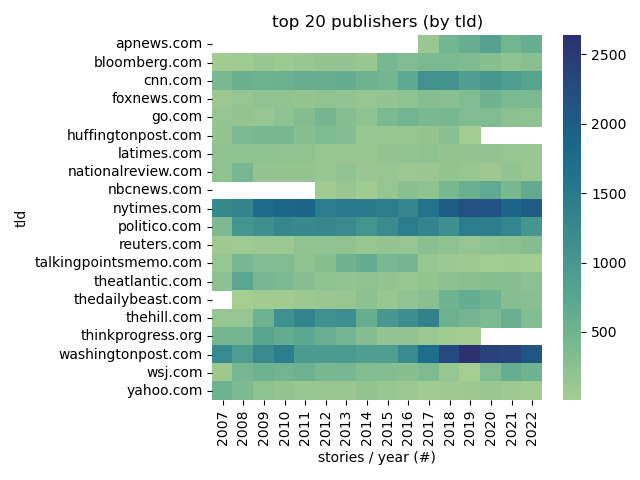
+# Descriptive Stats
+
+## Common TLDs
+
+
+
+Note:
+
+just for funs.
+
+Lots of IP addresses and spammy looking ones.
+
===
+
+
+# Data Structures
+
+## Bias
+
+==
+
+# Data Structures
+
+## Bias
+
+- Per publisher.
+ - name,
+ - label/ordinal value.
+ - agree/disagree vote by community.
+- Name could be semi-automatically joined to stories.
+
+==
+
+# Data Structures
+
+## Bias
+
+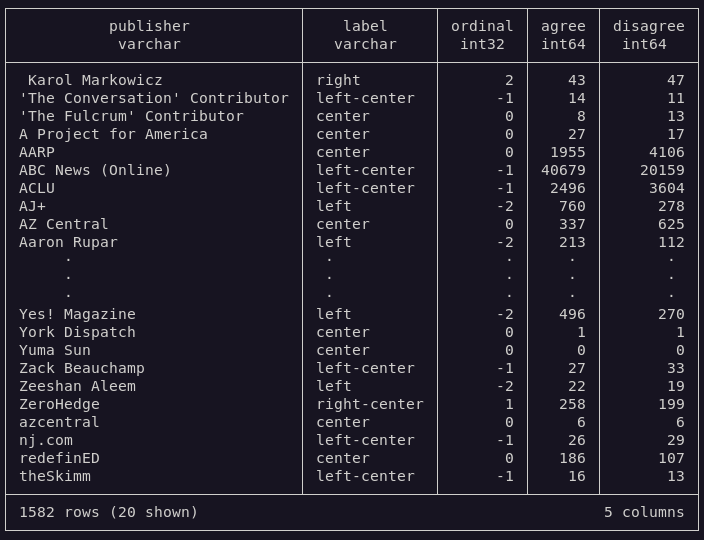
+
+Note:
+
+Later, media type and explicit ordinal values were added via api access.
+
+==
+
+# Data Selection
+
+## Bias
+
+- Keep all ratings.
+- Join datasets on publisher name.
+ - Started with 'jaro winkler similarity' then manually from there (look up Named Entity Recognition).
+- Use numeric values.
+ - [left: -2, left-center: -1, ...].
+ - Possibly scale ordinal based on agree/disagree ratio.
+
+Note:
+
+Lots of agrees on the ends of the spectrum implies their very left or very right.
+
+Lots of agrees in the middle implies very neutral?
+
+==
+
+# Data
+
+## Bias
+
+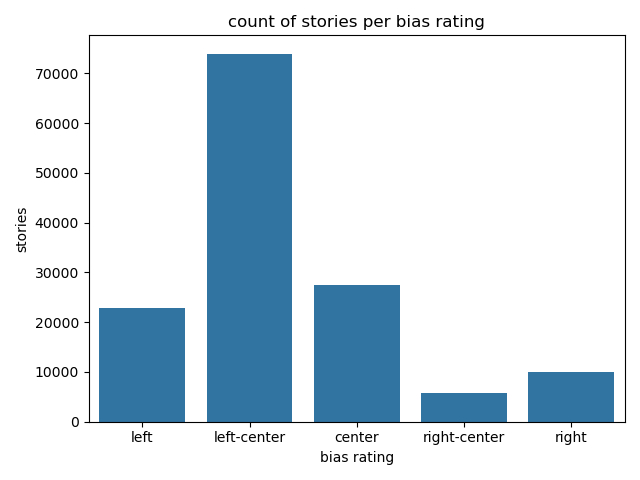
+
+==
+
+# Data
+
+## Bias
+
+
+
+Note:
+
+much smaller dataset.
+
+TODO: manually add more joins to story source.
+
+===
+
+
+
+# Data Structures
+
+## Embeddings
+
+==
+
+# Data Structures
+
+## Embeddings
+
+- Per story title.
+ - sentence embedding (n, 384) - **BERT**.
+ - sentiment classification (n, 1) - **RoBERTa base**.
+ - emotional classification (n, 1) - **RoBERTa Go-Emotions**.
+- ~ 1 hour of inference time to map story titles and descriptions.
+
+Note:
+
+RoBERTa - pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words.
+
+SST - Stanford Sentiment Treebank: 11,855 single sentences extracted from movie reviews, annotated by 3 human judges.
+
+==
+
+# Data Selection
+
+## Embeddings
+
+- Word embeddings were too complicated.
+- Kept argmax of classification prediction ([0.82, 0.18] -> LABEL_0).
+- For publisher based analysis, averaged sentence embeddings for all stories.
+
+==
+
+# Data
+
+## Embeddings
+
+| label | stories | publishers |
+|:---------|----------:|-------------:|
+| positive | 87830 | 223 |
+| negative | 163723 | 223 |
+
+Note:
+
+There was a model with a neutral label as well, but I opted out.
+
+==
+
+# Data
+
+## Embeddings
+
+| label | stories | publishers |
+|:---------|----------:|-------------:|
+| neutral | 124257 | 223 |
+| anger | 34124 | 223 |
+| fear | 36756 | 223 |
+| sadness | 27449 | 223 |
+| disgust | 17939 | 222 |
+| surprise | 5710 | 216 |
+| joy | 5318 | 214 |
+
+===
+
+
+
# Experiments
-1. **clustering** on link similarity.
-2. **classification** on link similarity.
-3. **classification** on sentence embedding.
-4. **classification** on sentiment analysis.
-5. **regression** on emotional classification over time and publication.
+==
+
+# Experiments
+
+1. **clustering** on link similarity.
+2. **classification** on link similarity.
+3. **classification** on sentence embedding.
+4. **classification** on sentiment analysis.
+5. **regression** on emotional classification over time and publication.
+
+Note:
+
+5 main experiments.
+
+Lots of tinkering and 'agile development'.
+
+Use source control.
===
+
+
# Experiment 1
**clustering** on link similarity.
@@ -392,12 +679,21 @@ Note:
Principle Component Analysis:
- a statistical technique for reducing the dimensionality of a dataset.
- linear transformation into a new coordinate system where (most of) the variation data can be described with fewer dimensions than the initial data.
+- I use it alot to map from high dimensional space (links adj. and embeddings) to lower, most significant space.
+
+==
+
+
+
+# Experiment 1
+
+## Encoding schemes
==
# Experiment 1
-## One Hot Encoding
+## One-hot Encoding
| publisher | nytimes| wsj| newsweek| ...|
|:----------|--------:|----:|--------:|----:|
@@ -446,7 +742,22 @@ The elbow method looks at the percentage of explained variance as a function of
One should choose a number of clusters so that adding another cluster doesn't give much better modeling of the data.
-Percentage of variance explained is the ratio of the between-group variance to the total variance,
+Percentage of variance explained is the ratio of the between-group variance to the total variance
+
+sklearn eliminated 2 cluster groups??
+
+==
+
+
+
+# Experiment 1
+
+## Comparing encoding schemes
+
+Note:
+
+They all have good clusters.
+
==
@@ -456,6 +767,12 @@ Percentage of variance explained is the ratio of the between-group variance to t
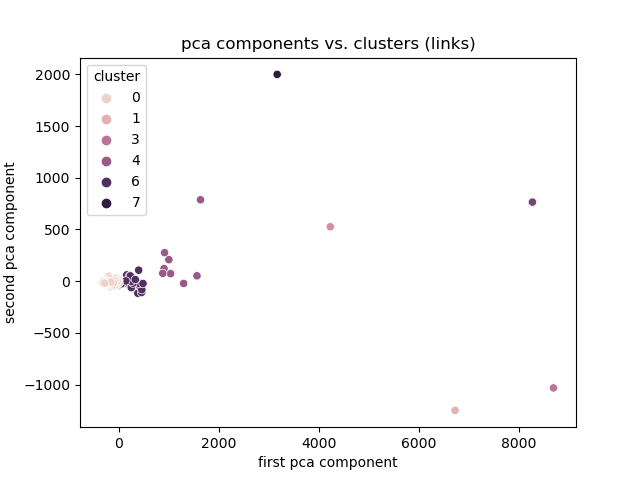
+Note:
+
+link frequency dominates one component.
+
+more interested in bias between publishers, not difference between mainstream and outliers.
+
==
# Experiment 1
@@ -464,28 +781,40 @@ Percentage of variance explained is the ratio of the between-group variance to t
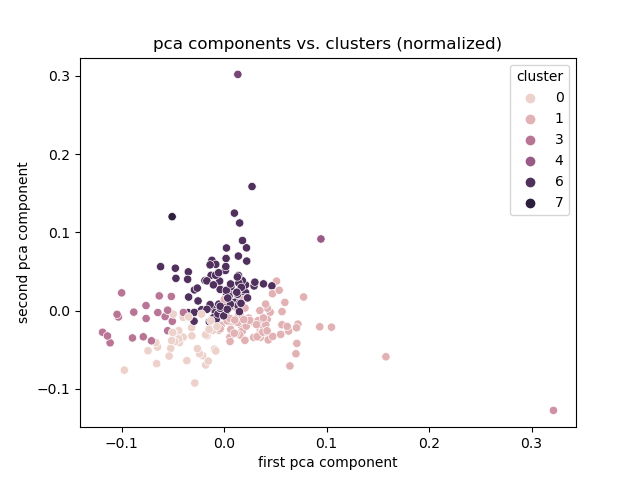
+Note:
+
+a few outliers still, but better.
+
==
# Experiment 1
-## One Hot
+## One-Hot
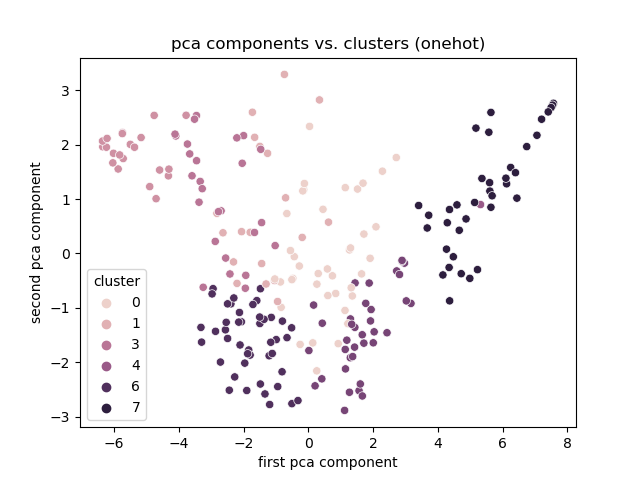
+Note:
+
+really dispursed
+
==
# Experiment 1
## Discussion
-- Best encoding: One hot.
-- Clusters, but no explanation.
+- One-hot seems to reflect the right features.
+- Found clusters, but meaning is arbitrary.
+ - map to PCA results nicely.
- Limitation: need the link encoding to cluster.
- Smaller publishers might not link very much.
- TODO: Association Rule Mining.
+ - 'Basket of goods' analysis to group publishers.
===
+
+
# Experiment 2
**classification** on link similarity.
@@ -496,8 +825,7 @@ Percentage of variance explained is the ratio of the between-group variance to t
## Setup
-- **clustering**.
-- Create features. :
+- Create features:
- Publisher frequency.
- Reuse link encodings.
- Create classes:
@@ -520,14 +848,42 @@ Note:
| right | 369 |
| agree range | [0.0-1.0] |
+Note:
+
+rehash of what bias data is available.
+
==
# Experiment 2
-## PCA + Labels
+## Results
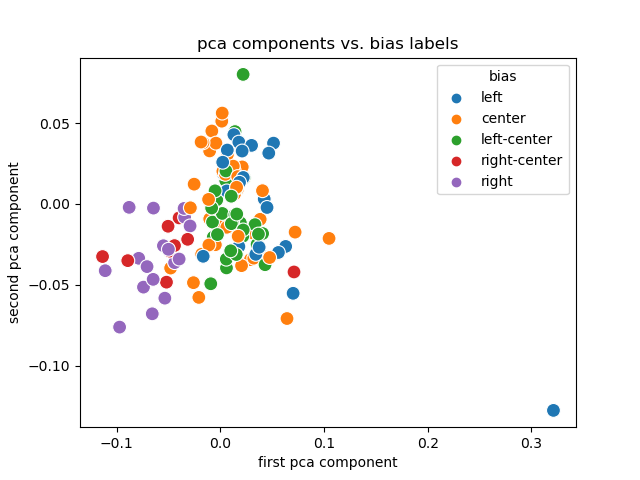
+Note:
+
+pca maps to bias labels well, left on one end, right on the other.
+
+if you squint.
+
+==
+
+# Experiment 2
+
+## Results
+
+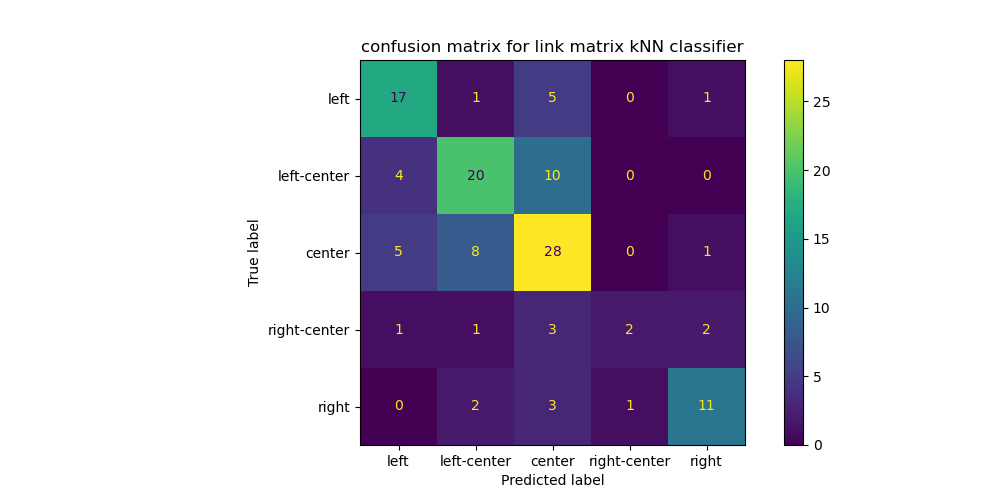
+
+Note:
+
+hot diagonal is good.
+
+all data.
+
+train test split only had 20 or so samples in it?
+
+overlap between link choices and bias ratings is slim.
+
==
# Experiment 2
@@ -537,6 +893,12 @@ Note:
- Link encodings (and their PCA) are useful.
- Labels are (sort of) separated and clustered.
- Creating them for smaller publishers is trivial.
+- Hot diagonal confusion matrix is good.
+- Need to link more publisher data to get good test data.
+
+Note:
+
+
==
# Experiment 2
@@ -544,13 +906,15 @@ Note:
## Limitations
- Dependent on accurate rating.
-- Ordinal ratings not available.
+- Ordinal ratings weren't available.
- Dependent on accurate joining across datasets.
- Entire publication is rated, not authors.
- Don't know what to do with community rating.
===
+
+
# Experiment 3
**classification** on sentence embedding.
@@ -561,22 +925,28 @@ Note:
## Setup
-
-- **classification**.
- Generate sentence embedding for each title.
- Rerun PCA analysis on title embeddings.
- Use kNN classifier to map embedding features to bias rating.
==
+
+
# Experiment 3
-## Sentence Embeddings
+## Embeddings Primer
+
+==
+
+# Experiment 3
+
+## Embedding Steps
1. Extract titles.
2. Tokenize titles.
-3. Pick pretrained Language Model.
-4. Generate embeddings from tokens.
+3. Pick pretrained language model.
+4. Generate embeddings from tokens using model.
==
@@ -657,6 +1027,19 @@ array([[ 0.12444635, -0.05962477, -0.00127911, ..., 0.13943022,
-0.29782432, 0.4289513 ],
...,
```
+
+Note:
+
+attention masks allow the model to ignore padding so all vectors are same length.
+
+embedding space has semantic meaning.
+
+can do vector math on them:
+
+king - man = monarch
+
+monarch + dance = happy?
+
==
# Experiment 3
@@ -666,7 +1049,10 @@ array([[ 0.12444635, -0.05962477, -0.00127911, ..., 0.13943022,
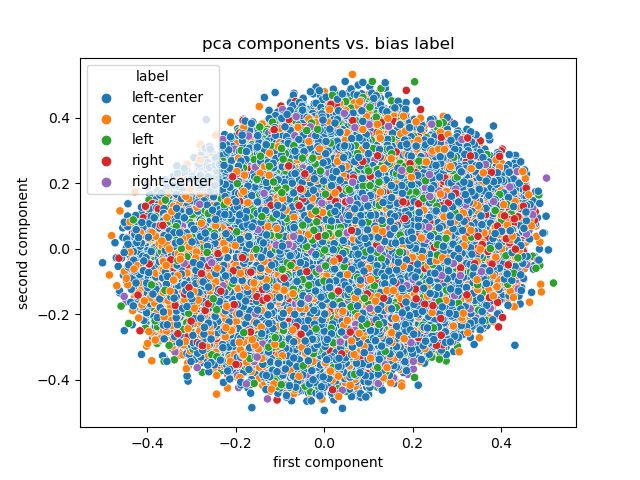
Note:
-Not a lot of information in PCA this time.
+
+pca on the sentence embeddings of the titles.
+
+not a lot of information in PCA this time.
==
@@ -678,8 +1064,13 @@ Not a lot of information in PCA this time.
Note:
+
What about average publisher embedding?
+centers are pushed outside?
+
+sorry about the color pallet.
+
==
# Experiment 3
@@ -695,6 +1086,8 @@ Set aside 20% of the data as a test set.
Once trained, compared the predictions with the true on the test set.
+not bad.
+
==
# Experiment 3
@@ -703,9 +1096,12 @@ Once trained, compared the predictions with the true on the test set.
- Embedding space is hard to condense with PCA.
- Maybe the classifier is learning to guess 'left-ish'?
+- Does DL work better on sparse inputs?
===
+
+
# Experiment 4
**classification** on sentiment analysis.
@@ -715,9 +1111,9 @@ Once trained, compared the predictions with the true on the test set.
## Setup
-- Use pretrained Language Classifier.
+- Use pretrained language classifier.
- Previously: Mapped twitter posts to tokens, to embedding, to ['positive', 'negative'] labels.
-- Predict: rate of neutral titles decreasing over time.
+- Predict: rate of neutral titles decreasing over time.
==
@@ -727,36 +1123,77 @@ Once trained, compared the predictions with the true on the test set.
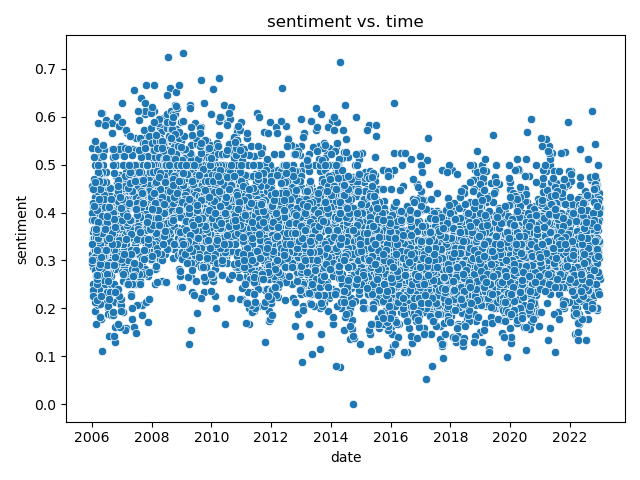
+Note:
+
+maybe there's something there.
+
+less positive after 2008?
+
+low around 2016?
+
+increase around 202?
+
+overall still lower.
+
==
+
# Experiment 4
## Results
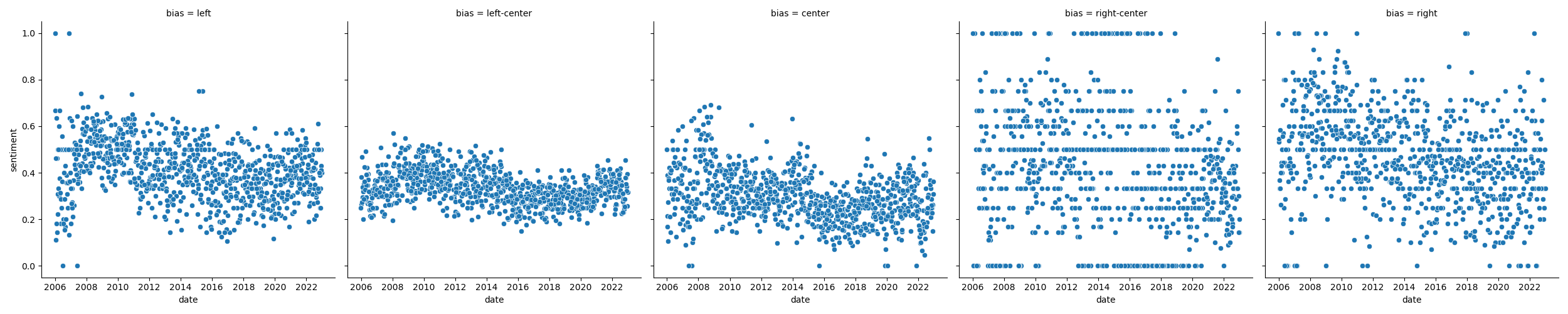
+Note:
+
+right has not a lot of data.
+
+all trend down over time.
+
+people loved Obama at the beginning.
+
+==
+
+# Experiment 4
+
+## Results
+
+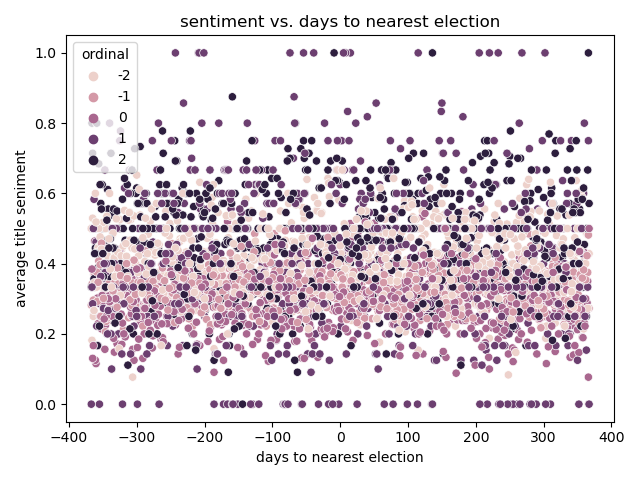
+
+Note:
+
+assumption: national elections drive news sentiment.
+
+expected a taller band in the middle then the edges.
+
==
# Experiment 4
## Discussion
--
+- Bump post Obama election for left and center.
+- Dip pre Trump election for left and center.
+- Right is all over the place - not enough data?
+- Recency of election not a clear factor.
===
+
+
# Experiment 5
-**regression** on emotional classification over time and publication.
+**regression** on title emotional expression.
==
+
# Experiment 5
## Setup
- Use pretrained language classifier.
- Previously: Mapped reddit posts to tokens, to embedding, to emotion labels.
-- Predict: rate of neutral titles decreasing over time.
-- Classify:
+- Predict: rate of neutral titles decreasing over time.
+- Classify:
- features: emotional labels
- labels: bias
@@ -768,6 +1205,14 @@ Once trained, compared the predictions with the true on the test set.
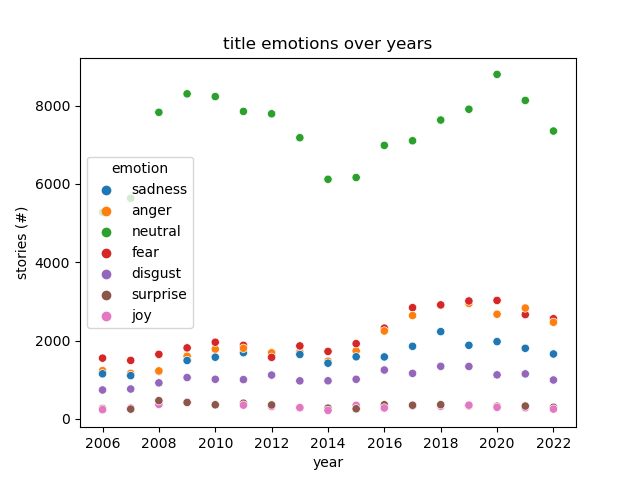
+Note:
+
+neutrality between Obama and Trump
+
+emotional titles all increased - shape of the underlying data.
+
+TODO: normalize relative expression.
+
==
# Experiment 5
@@ -776,6 +1221,10 @@ Once trained, compared the predictions with the true on the test set.
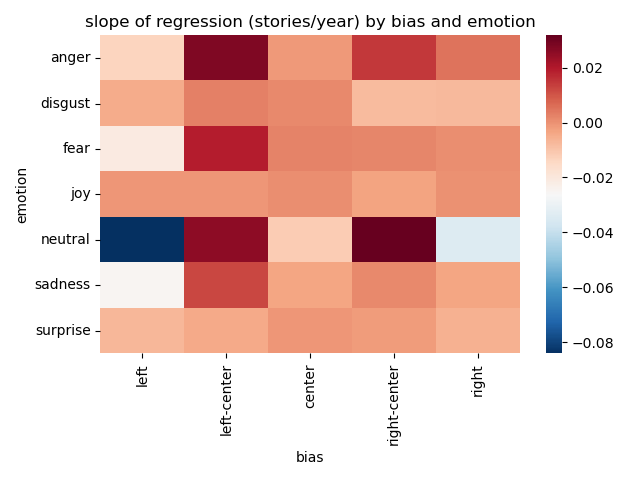
+Note:
+
+left and right got less neutral over time.
+
==
# Experiment 5
@@ -790,33 +1239,59 @@ Once trained, compared the predictions with the true on the test set.
===
-# Experiment 6 (**TODO**)
+
-## Setup
+# Conclusion
-- Have a lot of features now.
+==
+
+# Hypothesis
+
+- The polarization is not evenly distributed across publishers. **unproven**
+- The polarization is not evenly distributed across political specturm. **unproven**
+- The polarization increases near elections. **false**
+- Similarly polarized publishers link to each other. **sorta**
+- 'Mainstream' media uses more neutral titles. **true**
+- Highly polarized publications don't last as long. **untested**
+
+==
+
+# Conclusion
+
+- Article titles do not have a lot of predictive power.
+- Mainstream, neutral publications dominate the dataset.
+- Link frequency, sentence embeddings, and sentiments are useful features.
+- A few questions remain.
+
+Note:
+
+Experiment 6 (**TODO**)
+
+- Have a lot of features now.
- Link PCA components.
- Embedding PCA components.
- Sentiment.
- Emotion.
-- Can we predict with all of them: Bias.
-- End user: Is that useful? Where will I get all that at inference time?
+- Can we predict with all of them: Bias.
-===
+limitations
-# Overall Limitations
+- Many different authors under the same publisher.
+- Publishers use syndication.
+- Bias ratings are biased and not linked automaticall.
+- National news is generally designed to be neutral sounding.
+- End user: Is that useful? Where will I get all that at inference time?
-- Many different authors under the same publisher.
-- Publishers use syndication.
-- Bias ratings are biased.
-===
+==
+
+
# Questions
-===
+==
-
+
# References
diff --git a/src/cli.py b/src/cli.py
index 92c7b5c..a85457f 100644
--- a/src/cli.py
+++ b/src/cli.py
@@ -67,6 +67,7 @@ if __name__ == "__main__":
cli.add_command(plots.sentiment.over_time)
cli.add_command(plots.sentiment.bias_over_time)
+ cli.add_command(plots.sentiment.bias_vs_recent_winner)
cli()
diff --git a/src/data/scrape.py b/src/data/scrape.py
index d22ef75..a0d07c1 100644
--- a/src/data/scrape.py
+++ b/src/data/scrape.py
@@ -348,6 +348,7 @@ def create_elections_table():
row_number() over() as id
,type
,date
+ ,winner
FROM df
""")
@@ -359,6 +360,7 @@ def create_elections_table():
,e.id as election_id
,e.date as election_date
,s.published_at as publish_date
+ ,e.winner as winner
FROM (
SELECT
DISTINCT
@@ -373,6 +375,7 @@ def create_elections_table():
,publish_date
,election_date
,election_id
+ ,winner
FROM cte
)
SELECT
@@ -380,6 +383,7 @@ def create_elections_table():
,publish_date
,election_date
,election_id
+ ,winner
FROM windowed
WHERE rn = 1
""")
diff --git a/src/plots/bias.py b/src/plots/bias.py
new file mode 100644
index 0000000..5c3f79c
--- /dev/null
+++ b/src/plots/bias.py
@@ -0,0 +1,60 @@
+import click
+from data.main import connect
+import os
+from pathlib import Path
+import seaborn as sns
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+
+out_path = Path(os.getenv('DATA_MINING_DOC_DIR')) / 'figures'
+
+@click.command('plot:bias-hist')
+def hist():
+ filename = "bias_hist.png"
+
+ DB = connect()
+ data = DB.sql("""
+ SELECT
+ b.ordinal
+ ,count(1) as stories
+ FROM stories s
+ JOIN publisher_bias pb
+ ON pb.publisher_id = s.publisher_id
+ JOIN bias_ratings b
+ ON b.id = pb.bias_id
+ GROUP BY
+ b.ordinal
+ """).df()
+ DB.close()
+
+ ax = sns.barplot(x=data['ordinal'], y=data['stories'], color='tab:blue')
+ ticklabels = ['left', 'left-center', 'center', 'right-center', 'right']
+ ax.set(title="count of stories per bias rating", xlabel="bias rating", xticklabels=ticklabels)
+ plt.tight_layout()
+ plt.savefig(out_path / filename)
+ print(f"saved: {filename}")
+@click.command('plot:bias-publisher-hist')
+def publisher_hist():
+ filename = "bias_publisher_hist.png"
+
+ DB = connect()
+ data = DB.sql("""
+ SELECT
+ b.ordinal
+ ,count(1) as publishers
+ FROM publisher_bias pb
+ JOIN bias_ratings b
+ ON b.id = pb.bias_id
+ GROUP BY
+ b.ordinal
+ """).df()
+ DB.close()
+
+ ax = sns.barplot(x=data['ordinal'], y=data['publishers'], color='tab:blue')
+ ticklabels = ['left', 'left-center', 'center', 'right-center', 'right']
+ ax.set(title="count of publishers per bias rating", xlabel="bias rating", xticklabels=ticklabels)
+ plt.tight_layout()
+ plt.savefig(out_path / filename)
+ plt.close()
+ print(f"saved: {filename}")
diff --git a/src/plots/emotion.py b/src/plots/emotion.py
index b26071e..11666f1 100644
--- a/src/plots/emotion.py
+++ b/src/plots/emotion.py
@@ -115,3 +115,45 @@ def emotion_regression():
plt.tight_layout()
plt.savefig(out_path / filename)
print(f"saved: {filename}")
+
+@click.command('plot:emotion-hist')
+def emotion_hist():
+ filename = "emotion_hist.png"
+
+ DB = connect()
+ DB.query("""describe story_emotions""")
+
+ DB.query("""
+ select
+ e.label
+ ,count(distinct s.id) as stories
+ ,count(distinct s.publisher_id) as publishers
+ from story_emotions se
+ join emotions e
+ on e.id = se.emotion_id
+ join top.stories s
+ on s.id = se.story_id
+ group by
+ e.label
+ """).df().to_markdown(index=False)
+
+ data = DB.sql("""
+ SELECT
+ b.ordinal
+ ,count(1) as stories
+ FROM stories s
+ JOIN publisher_bias pb
+ ON pb.publisher_id = s.publisher_id
+ JOIN bias_ratings b
+ ON b.id = pb.bias_id
+ GROUP BY
+ b.ordinal
+ """).df()
+ DB.close()
+
+ ax = sns.barplot(x=data['ordinal'], y=data['stories'], color='tab:blue')
+ ticklabels = ['left', 'left-center', 'center', 'right-center', 'right']
+ ax.set(title="count of stories per bias rating", xlabel="bias rating", xticklabels=ticklabels)
+ plt.tight_layout()
+ plt.savefig(out_path / filename)
+ print(f"saved: {filename}")
diff --git a/src/plots/links.py b/src/plots/links.py
index 6526142..a5d1ada 100644
--- a/src/plots/links.py
+++ b/src/plots/links.py
@@ -112,3 +112,134 @@ def test():
# .df().to_csv(data_dir / 'cluster_publishers.csv', sep="|", index=False)
DB.close()
+
+@click.command('plot:link-confusion')
+def link_confusion():
+ from sklearn.model_selection import train_test_split
+ from sklearn.neighbors import KNeighborsClassifier
+ from sklearn.metrics import ConfusionMatrixDisplay
+
+ filename = "link_confusion.png"
+
+ DB = connect()
+ bias = DB.query("""
+ SELECT
+ p.id as publisher_id
+ ,b.ordinal
+ FROM top.publishers p
+ JOIN top.publisher_bias pb
+ ON pb.publisher_id = p.id
+ JOIN bias_ratings b
+ ON b.id = pb.bias_id
+ """).df()
+
+ df = DB.query("""
+ SELECT
+ *
+ FROM top.link_edges
+ WHERE parent_id in (
+ select
+ publisher_id
+ from bias
+ )
+ AND child_id in (
+ select
+ publisher_id
+ from bias
+ )
+ """).df()
+ pivot = df.pivot(index='parent_id', columns='child_id', values='links').fillna(0)
+
+ x = pivot.values
+ y = bias.sort_values('publisher_id').ordinal
+
+
+ x_train, x_test = train_test_split(x)
+ y_train, y_test = train_test_split(y)
+
+ model = KNeighborsClassifier(n_neighbors=5)
+ model.fit(x_train, y_train)
+ y_pred = model.predict(x_test)
+
+
+ fig, ax = plt.subplots(figsize=(10, 5))
+ ConfusionMatrixDisplay.from_predictions(y_test, y_pred, ax=ax)
+ ticklabels = ['left', 'left-center', 'center', 'right-center', 'right']
+ ax.set(title="confusion matrix for kNN classifier on test data.", xticklabels=ticklabels, yticklabels=ticklabels)
+ plt.savefig(out_dir / filename)
+ plt.close()
+ print(f"saved plot: {filename}")
+
+@click.command('plot:link-classifier')
+def link_confusion():
+ from sklearn.model_selection import train_test_split
+ from sklearn.neighbors import KNeighborsClassifier
+ from sklearn.metrics import ConfusionMatrixDisplay
+
+ filename = "link_confusion.png"
+
+ DB = connect()
+ bias = DB.query("""
+ SELECT
+ p.id as publisher_id
+ ,b.ordinal
+ FROM top.publishers p
+ JOIN top.publisher_bias pb
+ ON pb.publisher_id = p.id
+ JOIN bias_ratings b
+ ON b.id = pb.bias_id
+ """).df()
+
+ df = DB.query("""
+ SELECT
+ *
+ FROM top.link_edges
+ WHERE parent_id in (
+ select
+ publisher_id
+ from bias
+ )
+ AND child_id in (
+ select
+ publisher_id
+ from bias
+ )
+ """).df()
+ pivot = df.pivot(index='parent_id', columns='child_id', values='links').fillna(0)
+
+ x = pivot.values
+ y = bias.sort_values('publisher_id').ordinal
+
+ data = DB.query(f"""
+ SELECT
+ p.id as publisher_id
+ ,pca.first
+ ,pca.second
+ FROM top.publisher_pca_onehot pca
+ JOIN top.publishers p
+ ON pca.publisher_id = p.id
+ """).df()
+
+
+
+ model = KNeighborsClassifier(n_neighbors=5)
+ model.fit(x, y)
+ y_pred = model.predict(x)
+
+ plot = bias.sort_values('publisher_id')
+ plot['pred'] = y_pred
+ data = pd.merge(plot, data)
+
+
+ fig, ax = plt.subplots(figsize=(10, 5))
+ ConfusionMatrixDisplay.from_predictions(data['ordinal'], data['pred'], ax=ax)
+ ticklabels = ['left', 'left-center', 'center', 'right-center', 'right']
+ ax.set(title="confusion matrix for link matrix kNN classifier", xticklabels=ticklabels, yticklabels=ticklabels)
+ plt.savefig(out_dir / filename)
+ plt.close()
+ print(f"saved plot: {filename}")
+
+ ax = sns.scatterplot(x=data['first'], y=data['second'], hue=data['pred'])
+ plt.savefig(out_dir / filename)
+ plt.close()
+ print(f"saved plot: {filename}")
diff --git a/src/plots/sentiment.py b/src/plots/sentiment.py
index a0d24f6..7a9f48c 100644
--- a/src/plots/sentiment.py
+++ b/src/plots/sentiment.py
@@ -8,6 +8,7 @@ import numpy as np
import pandas as pd
out_path = Path(os.getenv('DATA_MINING_DOC_DIR')) / 'figures'
+
@click.command('plot:sentiment-over-time')
def over_time():
filename = "sentiment_over_time.png"
@@ -30,6 +31,7 @@ def over_time():
plt.tight_layout()
plt.savefig(out_path / filename)
print(f"saved: {filename}")
+
@click.command('plot:bias-vs-sentiment-over-time')
def bias_over_time():
filename = "bias_vs_sentiment_over_time.png"
@@ -38,8 +40,9 @@ def bias_over_time():
data = DB.sql("""
SELECT
avg(sent.class_id) as sentiment
- ,s.published_at as date
- ,b.id as bias_id
+ ,date_trunc('yearweek', s.published_at) as date
+ --,b.ordinal as ordinal
+ ,b.bias
FROM top.story_sentiments sent
JOIN top.stories s
ON s.id = sent.story_id
@@ -48,13 +51,88 @@ def bias_over_time():
JOIN bias_ratings b
ON b.id = pb.bias_id
GROUP BY
- s.published_at
- ,b.id
+ date_trunc('yearweek', s.published_at)
+ ,b.bias
""").df()
DB.close()
- ax = sns.relplot(x=data['date'], y=data['sentiment'], col=data['bias_id'])
- ax.set(title="sentiment vs. time grouped by bias")
+ order = ['left', 'left-center', 'center', 'right-center', 'right']
+ ax = sns.relplot(data, x='date', y='sentiment', col='bias', col_order=order)
+ plt.tight_layout()
+ plt.savefig(out_path / filename)
+ plt.close()
+ print(f"saved: {filename}")
+
+@click.command('plot:sentiment-recent-winner')
+def bias_vs_recent_winner():
+ filename = "bias_vs_recent_winner.png"
+
+ DB = connect()
+ data = DB.sql("""
+ SELECT
+ e.days_away as days_away
+ ,b.ordinal
+ ,avg(sent.class_id) as sentiment
+ ,count(1) as stories
+ FROM top.stories s
+ JOIN top.story_sentiments sent
+ ON s.id = sent.story_id
+ JOIN election_distance e
+ ON e.publish_date = s.published_at
+ JOIN publisher_bias pb
+ ON pb.publisher_id = s.publisher_id
+ JOIN bias_ratings b
+ ON b.id = pb.bias_id
+ GROUP BY
+ e.days_away
+ ,b.ordinal
+ """).df()
+ DB.close()
+ data
+
+ ax = sns.scatterplot(x=data['days_away'], y=data['sentiment'], hue=data['ordinal'])
+ ax.set(title="sentiment vs. days to nearest election", xlabel="days to nearest election", ylabel="average title seniment")
+ plt.tight_layout()
+ plt.savefig(out_path / filename)
+ plt.close()
+
+ print(f"saved: {filename}")
+
+@click.command('plot:sentiment-hist')
+def sentiment_hist():
+ filename = "sentiment_hist.png"
+
+ DB = connect()
+
+ DB.query("""
+ select
+ sent.label
+ ,count(distinct s.id) as stories
+ ,count(distinct s.publisher_id) as publishers
+ from top.story_sentiments sent
+ join top.stories s
+ on s.id = sent.story_id
+ group by
+ sent.label
+ """).df().to_markdown(index=False)
+
+ data = DB.sql("""
+ SELECT
+ b.ordinal
+ ,count(1) as stories
+ FROM stories s
+ JOIN publisher_bias pb
+ ON pb.publisher_id = s.publisher_id
+ JOIN bias_ratings b
+ ON b.id = pb.bias_id
+ GROUP BY
+ b.ordinal
+ """).df()
+ DB.close()
+
+ ax = sns.barplot(x=data['ordinal'], y=data['stories'], color='tab:blue')
+ ticklabels = ['left', 'left-center', 'center', 'right-center', 'right']
+ ax.set(title="count of stories per bias rating", xlabel="bias rating", xticklabels=ticklabels)
plt.tight_layout()
plt.savefig(out_path / filename)
print(f"saved: {filename}")