add exp 4/5
This commit is contained in:
BIN
docs/figures/avg_embedding_sentence_pca.png
Normal file
BIN
docs/figures/avg_embedding_sentence_pca.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 51 KiB |
BIN
docs/figures/embedding_sentence_pca.png
Normal file
BIN
docs/figures/embedding_sentence_pca.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 275 KiB |
BIN
docs/figures/emotion_over_time.png
Normal file
BIN
docs/figures/emotion_over_time.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 44 KiB |
BIN
docs/figures/emotion_regression.png
Normal file
BIN
docs/figures/emotion_regression.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 30 KiB |
BIN
docs/figures/sentence_confusion.png
Normal file
BIN
docs/figures/sentence_confusion.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 44 KiB |
BIN
docs/figures/sentiment_over_time.png
Normal file
BIN
docs/figures/sentiment_over_time.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 128 KiB |
@@ -54,6 +54,11 @@ allsides.com <!-- .element: class="fragment" -->
|
||||
|
||||
huggingface.com <!-- .element: class="fragment" -->
|
||||
|
||||
Note:
|
||||
Let's get a handle on the shape of the data.
|
||||
|
||||
The sources, size, and features of the data.
|
||||
|
||||
===
|
||||
|
||||
<section data-background-iframe="https://www.memeorandum.com" data-background-interactive></section>
|
||||
@@ -128,7 +133,7 @@ huggingface.com <!-- .element: class="fragment" -->
|
||||
===
|
||||
|
||||
# Data Structures
|
||||
Stories
|
||||
## Stories
|
||||
|
||||
- Top level stories. <!-- .element: class="fragment" -->
|
||||
- title.
|
||||
@@ -142,7 +147,7 @@ Stories
|
||||
==
|
||||
|
||||
# Data Structures
|
||||
Bias
|
||||
## Bias
|
||||
|
||||
- Per publisher. <!-- .element: class="fragment" -->
|
||||
- name.
|
||||
@@ -153,7 +158,7 @@ Bias
|
||||
==
|
||||
|
||||
# Data Structures
|
||||
Embeddings
|
||||
## Embeddings
|
||||
|
||||
- Per story title. <!-- .element: class="fragment" -->
|
||||
- sentence embedding (n, 384).
|
||||
@@ -169,7 +174,7 @@ Embeddings
|
||||
|
||||
# Data Collection
|
||||
|
||||
Story Scraper (simplified)
|
||||
## Story Scraper (simplified)
|
||||
|
||||
```python
|
||||
day = timedelta(days=1)
|
||||
@@ -187,7 +192,8 @@ while cur <= end:
|
||||
==
|
||||
|
||||
# Data Collection
|
||||
Bias Scraper (hard)
|
||||
|
||||
## Bias Scraper (hard)
|
||||
|
||||
```python
|
||||
...
|
||||
@@ -206,14 +212,16 @@ for row in rows:
|
||||
==
|
||||
|
||||
# Data Collection
|
||||
Bias Scraper (easy)
|
||||
|
||||
## Bias Scraper (easy)
|
||||
|
||||
|
||||
|
||||
==
|
||||
|
||||
# Data Collection
|
||||
Embeddings (easy)
|
||||
|
||||
## Embeddings (easy)
|
||||
|
||||
```python
|
||||
# table = ...
|
||||
@@ -230,7 +238,8 @@ for chunk in table:
|
||||
==
|
||||
|
||||
# Data Collection
|
||||
Classification Embeddings (medium)
|
||||
|
||||
## Classification Embeddings (medium)
|
||||
|
||||
```python
|
||||
...
|
||||
@@ -249,7 +258,8 @@ for i, class_id in enumerate(class_ids):
|
||||
==
|
||||
|
||||
# Data Selection
|
||||
Stories
|
||||
|
||||
## Stories
|
||||
|
||||
- Clip the first and last full year of stories. <!-- .element: class="fragment" -->
|
||||
- Remove duplicate stories (big stories span multiple days). <!-- .element: class="fragment" -->
|
||||
@@ -257,7 +267,7 @@ Stories
|
||||
==
|
||||
# Data Selection
|
||||
|
||||
Publishers
|
||||
## Publishers
|
||||
|
||||
- Combine subdomains of stories. <!-- .element: class="fragment" -->
|
||||
- blog.washingtonpost.com and washingtonpost.com are considered the same publisher.
|
||||
@@ -267,7 +277,7 @@ Publishers
|
||||
|
||||
# Data Selection
|
||||
|
||||
Links
|
||||
## Links
|
||||
|
||||
- Select only stories with publishers whose story had been a 'parent' ('original publishers'). <!-- .element: class="fragment" -->
|
||||
- Eliminates small blogs and non-original news.
|
||||
@@ -279,7 +289,7 @@ Links
|
||||
|
||||
# Data Selection
|
||||
|
||||
Bias
|
||||
## Bias
|
||||
|
||||
- Keep all ratings, even ones with low agree/disagree ratio.
|
||||
- Join datasets on publisher name.
|
||||
@@ -292,7 +302,7 @@ Bias
|
||||
|
||||
# Descriptive Stats
|
||||
|
||||
Raw
|
||||
## Raw
|
||||
|
||||
| metric | value |
|
||||
|:------------------|--------:|
|
||||
@@ -307,7 +317,7 @@ Raw
|
||||
==
|
||||
# Descriptive Stats
|
||||
|
||||
Stories Per Publisher
|
||||
## Stories Per Publisher
|
||||
|
||||

|
||||
|
||||
@@ -315,7 +325,7 @@ Stories Per Publisher
|
||||
|
||||
# Descriptive Stats
|
||||
|
||||
Top Publishers
|
||||
## Top Publishers
|
||||
|
||||
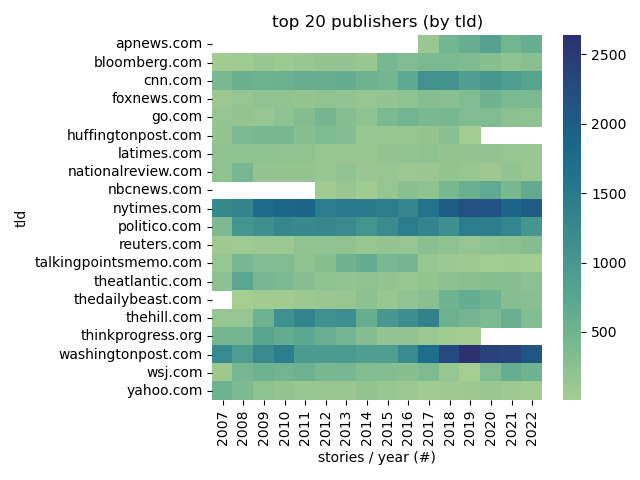
|
||||
|
||||
@@ -323,7 +333,7 @@ Top Publishers
|
||||
|
||||
# Descriptive Stats
|
||||
|
||||
Articles Per Year
|
||||
## Articles Per Year
|
||||
|
||||
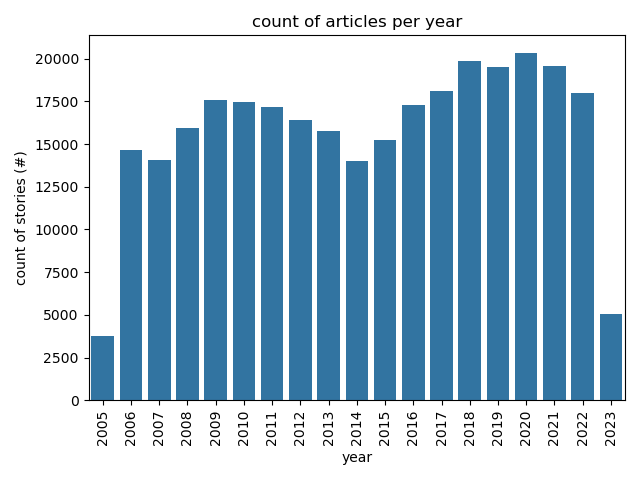
|
||||
|
||||
@@ -331,7 +341,7 @@ Articles Per Year
|
||||
|
||||
# Descriptive Stats
|
||||
|
||||
Common TLDs
|
||||
## Common TLDs
|
||||
|
||||
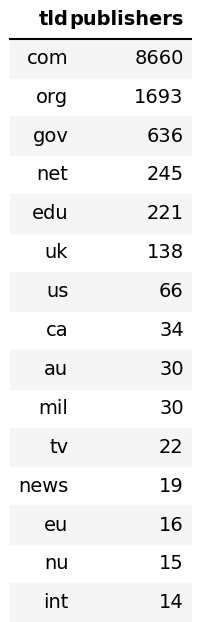
|
||||
|
||||
@@ -339,9 +349,9 @@ Common TLDs
|
||||
|
||||
# Descriptive Stats
|
||||
|
||||
Post Process
|
||||
## Post Process
|
||||
|
||||
| key | value |
|
||||
| metric | value |
|
||||
|:------------------|--------:|
|
||||
| total stories | 251553 |
|
||||
| total related | 815183 |
|
||||
@@ -352,6 +362,7 @@ Post Process
|
||||
| top level domains | 234 |
|
||||
|
||||
===
|
||||
|
||||
# Experiments
|
||||
|
||||
1. **clustering** on link similarity. <!-- .element: class="fragment" -->
|
||||
@@ -361,9 +372,16 @@ Post Process
|
||||
5. **regression** on emotional classification over time and publication. <!-- .element: class="fragment" -->
|
||||
|
||||
===
|
||||
|
||||
# Experiment 1
|
||||
|
||||
Setup
|
||||
**clustering** on link similarity.
|
||||
|
||||
==
|
||||
|
||||
# Experiment 1
|
||||
|
||||
## Setup
|
||||
|
||||
- Create one-hot encoding of links between publishers. <!-- .element: class="fragment" -->
|
||||
- Cluster the encoding. <!-- .element: class="fragment" -->
|
||||
@@ -379,7 +397,7 @@ Principle Component Analysis:
|
||||
|
||||
# Experiment 1
|
||||
|
||||
One Hot Encoding
|
||||
## One Hot Encoding
|
||||
|
||||
| publisher | nytimes| wsj| newsweek| ...|
|
||||
|:----------|--------:|----:|--------:|----:|
|
||||
@@ -392,7 +410,7 @@ One Hot Encoding
|
||||
|
||||
# Experiment 1
|
||||
|
||||
n-Hot Encoding
|
||||
## n-Hot Encoding
|
||||
|
||||
| publisher | nytimes| wsj| newsweek| ...|
|
||||
|:----------|--------:|----:|--------:|----:|
|
||||
@@ -405,7 +423,7 @@ n-Hot Encoding
|
||||
|
||||
# Experiment 1
|
||||
|
||||
Normalized n-Hot Encoding
|
||||
## Normalized n-Hot Encoding
|
||||
|
||||
| publisher | nytimes| wsj| newsweek| ...|
|
||||
|:----------|--------:|----:|--------:|----:|
|
||||
@@ -418,7 +436,7 @@ Normalized n-Hot Encoding
|
||||
|
||||
# Experiment 1
|
||||
|
||||
Elbow criterion
|
||||
## Elbow criterion
|
||||
|
||||
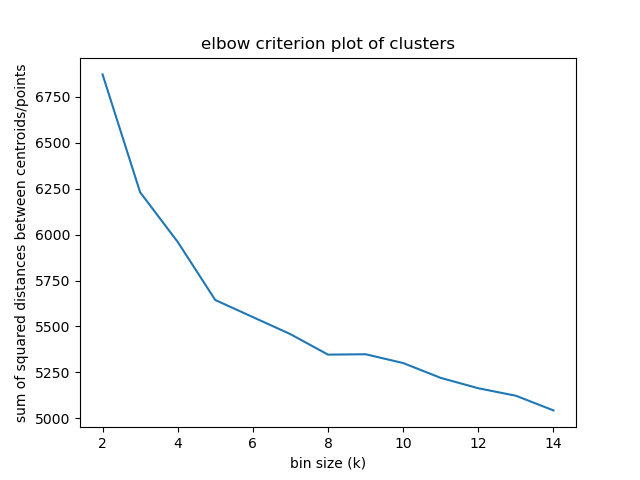
|
||||
|
||||
@@ -434,7 +452,7 @@ Percentage of variance explained is the ratio of the between-group variance to t
|
||||
|
||||
# Experiment 1
|
||||
|
||||
Link Magnitude
|
||||
## Link Magnitude
|
||||
|
||||
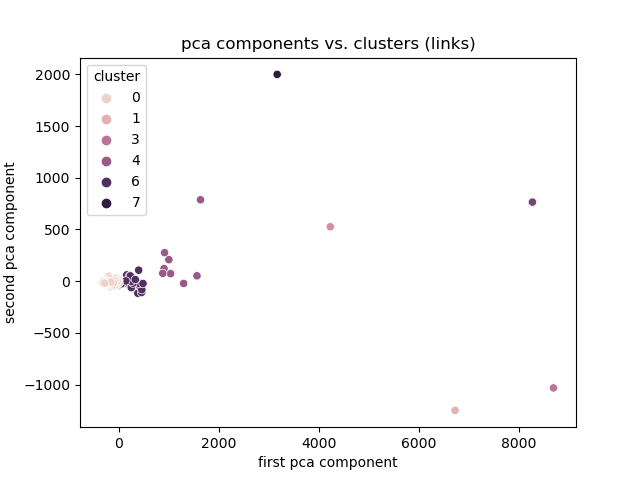
|
||||
|
||||
@@ -442,7 +460,7 @@ Link Magnitude
|
||||
|
||||
# Experiment 1
|
||||
|
||||
Normalized
|
||||
## Normalized
|
||||
|
||||
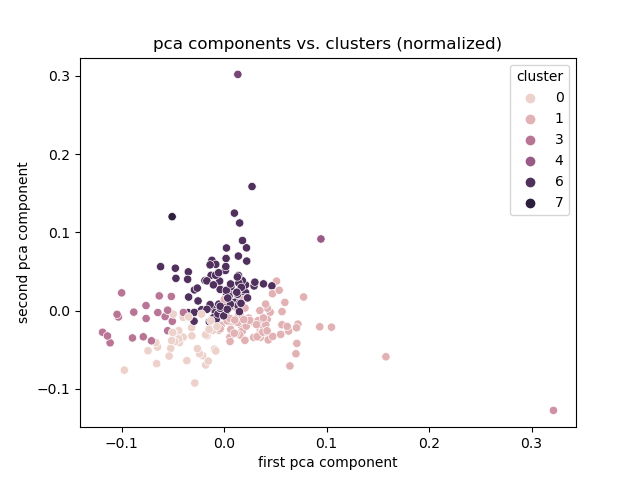
|
||||
|
||||
@@ -450,7 +468,7 @@ Normalized
|
||||
|
||||
# Experiment 1
|
||||
|
||||
Onehot
|
||||
## One Hot
|
||||
|
||||
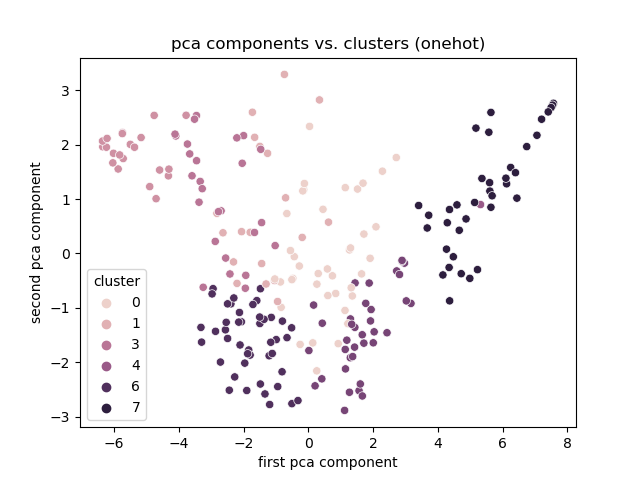
|
||||
|
||||
@@ -458,20 +476,27 @@ Onehot
|
||||
|
||||
# Experiment 1
|
||||
|
||||
Discussion
|
||||
## Discussion
|
||||
|
||||
- Best encoding: One hot. <!-- .element: class="fragment" -->
|
||||
- Clusters based on total links otherwise.
|
||||
- Clusters, but no explanation
|
||||
- Limitation: need the link encoding to cluster.
|
||||
- Clusters, but no explanation. <!-- .element: class="fragment" -->
|
||||
- Limitation: need the link encoding to cluster. <!-- .element: class="fragment" -->
|
||||
- Smaller publishers might not link very much.
|
||||
- TODO: Association Rule Mining. <!-- .element: class="fragment" -->
|
||||
|
||||
===
|
||||
|
||||
# Experiment 2
|
||||
|
||||
Setup
|
||||
**classification** on link similarity.
|
||||
|
||||
==
|
||||
|
||||
# Experiment 2
|
||||
|
||||
## Setup
|
||||
|
||||
- **clustering**. <!-- .element: class="fragment" -->
|
||||
- Create features. <!-- .element: class="fragment" -->:
|
||||
- Publisher frequency.
|
||||
- Reuse link encodings.
|
||||
@@ -483,7 +508,8 @@ Note:
|
||||
|
||||
==
|
||||
# Experiment 2
|
||||
Descriptive stats
|
||||
|
||||
## Descriptive stats
|
||||
|
||||
| metric | value |
|
||||
|:------------|:----------|
|
||||
@@ -498,7 +524,7 @@ Descriptive stats
|
||||
|
||||
# Experiment 2
|
||||
|
||||
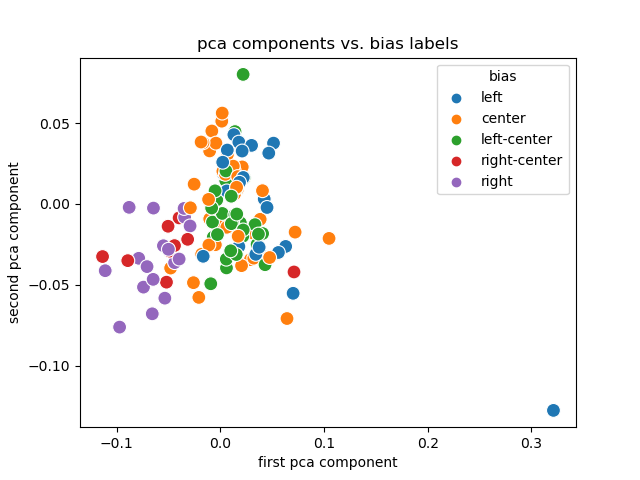
PCA + Labels
|
||||
## PCA + Labels
|
||||
|
||||
|
||||
|
||||
@@ -506,7 +532,7 @@ PCA + Labels
|
||||
|
||||
# Experiment 2
|
||||
|
||||
Discussion
|
||||
## Discussion
|
||||
|
||||
- Link encodings (and their PCA) are useful. <!-- .element: class="fragment" -->
|
||||
- Labels are (sort of) separated and clustered.
|
||||
@@ -515,7 +541,7 @@ Discussion
|
||||
|
||||
# Experiment 2
|
||||
|
||||
Limitations
|
||||
## Limitations
|
||||
|
||||
- Dependent on accurate rating. <!-- .element: class="fragment" -->
|
||||
- Ordinal ratings not available. <!-- .element: class="fragment" -->
|
||||
@@ -525,13 +551,260 @@ Limitations
|
||||
|
||||
===
|
||||
|
||||
# Experiment 3
|
||||
# Experiment 3
|
||||
|
||||
Setup
|
||||
**classification** on sentence embedding.
|
||||
|
||||
==
|
||||
|
||||
# Limitations
|
||||
# Experiment 3
|
||||
|
||||
## Setup
|
||||
|
||||
|
||||
- **classification**. <!-- .element: class="fragment" -->
|
||||
- Generate sentence embedding for each title. <!-- .element: class="fragment" -->
|
||||
- Rerun PCA analysis on title embeddings. <!-- .element: class="fragment" -->
|
||||
- Use kNN classifier to map embedding features to bias rating. <!-- .element: class="fragment" -->
|
||||
|
||||
==
|
||||
|
||||
# Experiment 3
|
||||
|
||||
## Sentence Embeddings
|
||||
|
||||
1. Extract titles.
|
||||
2. Tokenize titles.
|
||||
3. Pick pretrained Language Model.
|
||||
4. Generate embeddings from tokens.
|
||||
|
||||
==
|
||||
|
||||
# Experiment 3
|
||||
|
||||
## Tokens
|
||||
|
||||
**The sentence:**
|
||||
|
||||
"Spain, Land of 10 P.M. Dinners, Asks if It's Time to Reset Clock"
|
||||
|
||||
**Tokenizes to:**
|
||||
|
||||
```
|
||||
['[CLS]', 'spain', ',', 'land', 'of', '10', 'p', '.', 'm', '.',
|
||||
'dinners', ',', 'asks', 'if', 'it', "'", 's', 'time', 'to',
|
||||
'reset', 'clock', '[SEP]']
|
||||
```
|
||||
|
||||
Note:
|
||||
[CLS] is unique to BERT models and stands for classification.
|
||||
|
||||
==
|
||||
|
||||
# Experiment 3
|
||||
|
||||
## Tokens
|
||||
|
||||
**The sentence:**
|
||||
|
||||
"NPR/PBS NewsHour/Marist Poll Results and Analysis"
|
||||
|
||||
**Tokenizes to:**
|
||||
|
||||
```
|
||||
['[CLS]', 'npr', '/', 'pbs', 'news', '##ho', '##ur', '/', 'maris',
|
||||
'##t', 'poll', 'results', 'and', 'analysis', '[SEP]', '[PAD]',
|
||||
'[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']
|
||||
```
|
||||
|
||||
Note:
|
||||
The padding is there to make all tokenized vectors equal length.
|
||||
|
||||
The tokenizer also outputs a mask vector that the language model uses to ignore the padding.
|
||||
|
||||
==
|
||||
|
||||
# Experiment 3
|
||||
|
||||
## Embeddings
|
||||
|
||||
- Using a BERT (Bidirectional Encoder Representations from Transformers) based model.
|
||||
- Input: tokens.
|
||||
- Output: dense vectors representing 'semantic meaning' of tokens.
|
||||
|
||||
==
|
||||
|
||||
# Experiment 3
|
||||
|
||||
## Embeddings
|
||||
|
||||
**The tokens:**
|
||||
|
||||
```
|
||||
['[CLS]', 'npr', '/', 'pbs', 'news', '##ho', '##ur', '/', 'maris',
|
||||
'##t', 'poll', 'results', 'and', 'analysis', '[SEP]', '[PAD]',
|
||||
'[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']
|
||||
```
|
||||
|
||||
**Embeds to a vector (1, 384):**
|
||||
|
||||
```
|
||||
array([[ 0.12444635, -0.05962477, -0.00127911, ..., 0.13943022,
|
||||
-0.2552534 , -0.00238779],
|
||||
[ 0.01535596, -0.05933844, -0.0099495 , ..., 0.48110735,
|
||||
0.1370568 , 0.3285091 ],
|
||||
[ 0.2831368 , -0.4200529 , 0.10879617, ..., 0.15663117,
|
||||
-0.29782432, 0.4289513 ],
|
||||
...,
|
||||
```
|
||||
==
|
||||
|
||||
# Experiment 3
|
||||
|
||||
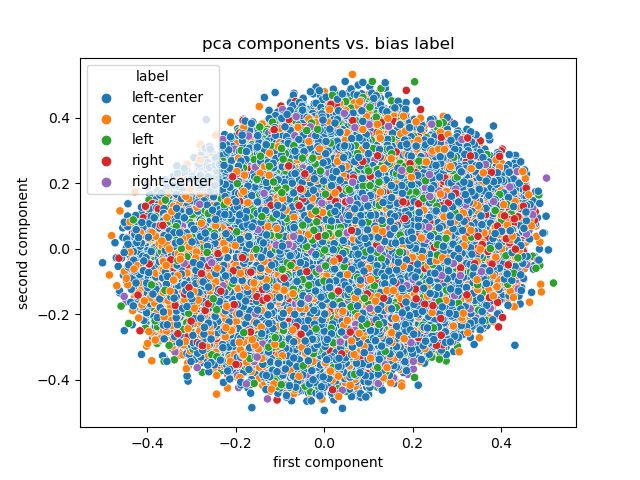
## Results
|
||||
|
||||
|
||||
|
||||
Note:
|
||||
Not a lot of information in PCA this time.
|
||||
|
||||
==
|
||||
|
||||
# Experiment 3
|
||||
|
||||
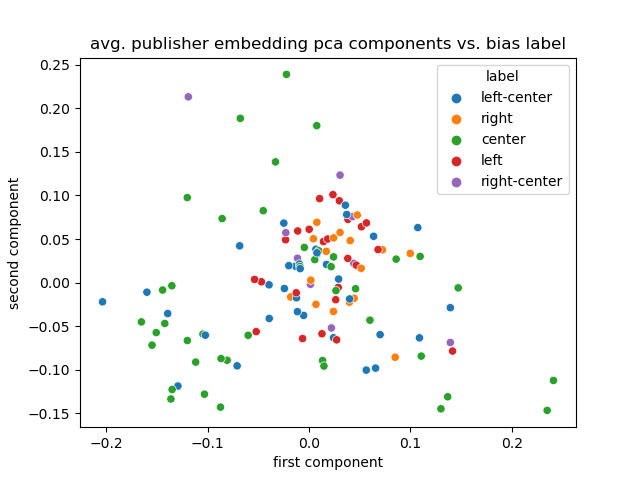
## Results
|
||||
|
||||
 <!-- .element: class="r-stretch" -->
|
||||
|
||||
|
||||
Note:
|
||||
What about average publisher embedding?
|
||||
|
||||
==
|
||||
|
||||
# Experiment 3
|
||||
|
||||
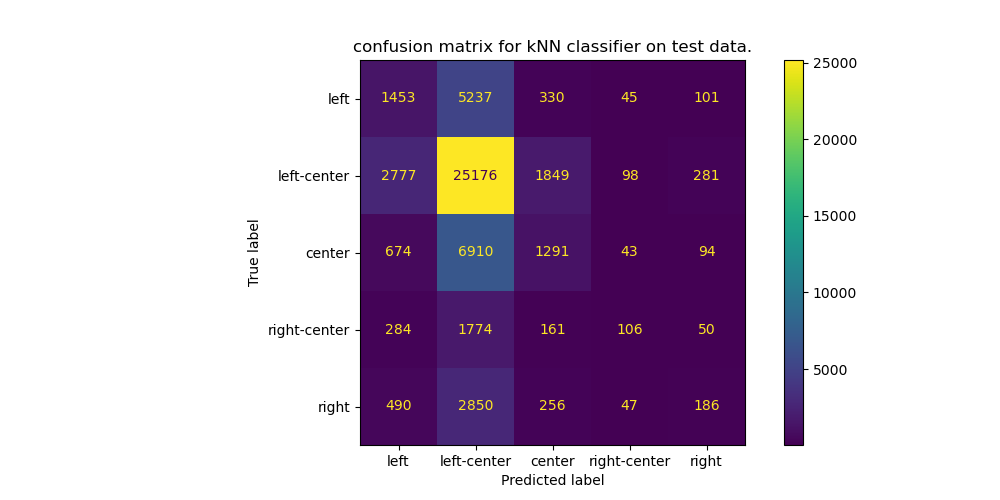
## Results
|
||||
|
||||
|
||||
|
||||
Note:
|
||||
Trained a kNN from sklearn.
|
||||
|
||||
Set aside 20% of the data as a test set.
|
||||
|
||||
Once trained, compared the predictions with the true on the test set.
|
||||
|
||||
==
|
||||
|
||||
# Experiment 3
|
||||
|
||||
## Discussion
|
||||
|
||||
- Embedding space is hard to condense with PCA. <!-- .element: class="fragment" -->
|
||||
- Maybe the classifier is learning to guess 'left-ish'? <!-- .element: class="fragment" -->
|
||||
|
||||
===
|
||||
|
||||
# Experiment 4
|
||||
|
||||
**classification** on sentiment analysis.
|
||||
|
||||
==
|
||||
# Experiment 4
|
||||
|
||||
## Setup
|
||||
|
||||
- Use pretrained Language Classifier. <!-- .element: class="fragment" -->
|
||||
- Previously: Mapped twitter posts to tokens, to embedding, to ['positive', 'negative'] labels. <!-- .element: class="fragment" -->
|
||||
- Predict: rate of neutral titles decreasing over time.
|
||||
|
||||
==
|
||||
|
||||
# Experiment 4
|
||||
|
||||
## Results
|
||||
|
||||
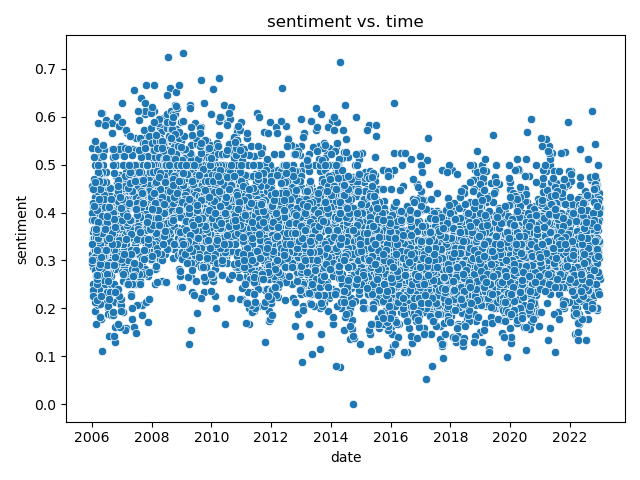
|
||||
|
||||
==
|
||||
# Experiment 4
|
||||
|
||||
## Results
|
||||
|
||||
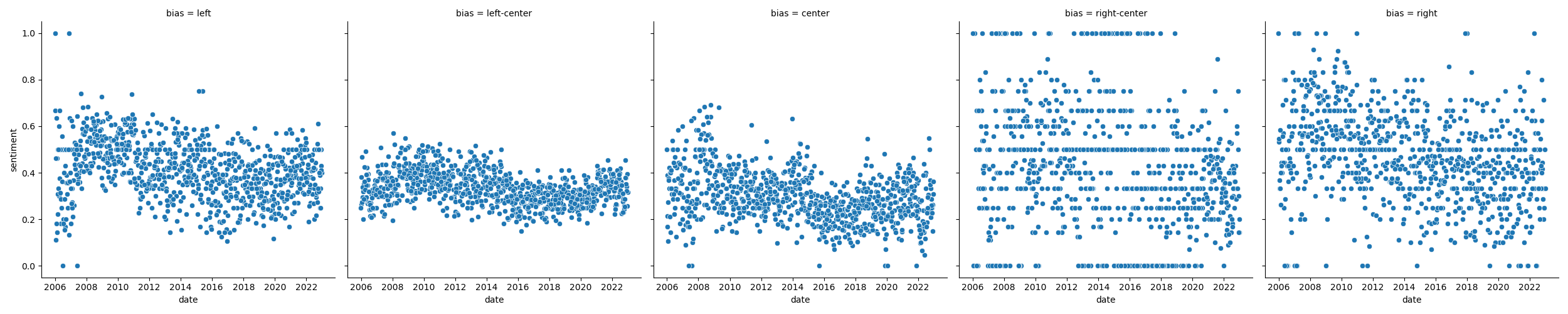
|
||||
|
||||
==
|
||||
|
||||
# Experiment 4
|
||||
|
||||
## Discussion
|
||||
|
||||
-
|
||||
|
||||
===
|
||||
|
||||
# Experiment 5
|
||||
|
||||
**regression** on emotional classification over time and publication.
|
||||
|
||||
==
|
||||
# Experiment 5
|
||||
|
||||
## Setup
|
||||
|
||||
- Use pretrained language classifier. <!-- .element: class="fragment" -->
|
||||
- Previously: Mapped reddit posts to tokens, to embedding, to emotion labels. <!-- .element: class="fragment" -->
|
||||
- Predict: rate of neutral titles decreasing over time.
|
||||
- Classify:
|
||||
- features: emotional labels
|
||||
- labels: bias
|
||||
|
||||
==
|
||||
|
||||
# Experiment 5
|
||||
|
||||
## Results
|
||||
|
||||
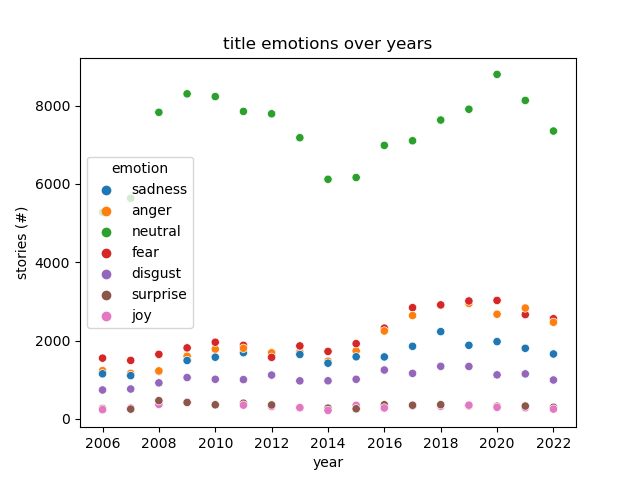
|
||||
|
||||
==
|
||||
|
||||
# Experiment 5
|
||||
|
||||
## Results
|
||||
|
||||
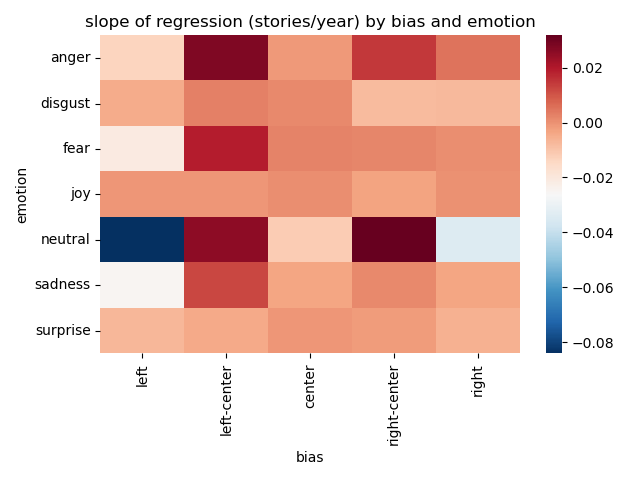
|
||||
|
||||
==
|
||||
|
||||
# Experiment 5
|
||||
|
||||
## Discussion
|
||||
|
||||
- Neutral story titles dominate the dataset. <!-- .element: class="fragment" -->
|
||||
- Increase in stories published might explain most of the trend. <!-- .element: class="fragment" -->
|
||||
- Far-right and far-left both became less neutral. <!-- .element: class="fragment" -->
|
||||
- Left-Center and right-center became more emotional, but also neutral. <!-- .element: class="fragment" -->
|
||||
- Not a lot of movement overall. <!-- .element: class="fragment" -->
|
||||
|
||||
===
|
||||
|
||||
# Experiment 6 (**TODO**)
|
||||
|
||||
## Setup
|
||||
|
||||
- Have a lot of features now. <!-- .element: class="fragment" -->
|
||||
- Link PCA components.
|
||||
- Embedding PCA components.
|
||||
- Sentiment.
|
||||
- Emotion.
|
||||
- Can we predict with all of them: Bias. <!-- .element: class="fragment" -->
|
||||
- End user: Is that useful? Where will I get all that at inference time? <!-- .element: class="fragment" -->
|
||||
|
||||
===
|
||||
|
||||
# Overall Limitations
|
||||
|
||||
- Many different authors under the same publisher. <!-- .element: class="fragment" -->
|
||||
- Publishers use syndication. <!-- .element: class="fragment" -->
|
||||
|
||||
Reference in New Issue
Block a user